Ball Tree Nearest Neighbor

Knn 15 K D Tree Algorithm Youtube

Kd Tree Algorithm How It Works Youtube

Pdf Ball Tree Efficient Spatial Indexing For Constrained

Module 04 Algorithms Topic 07 Instance Based Learning Ppt
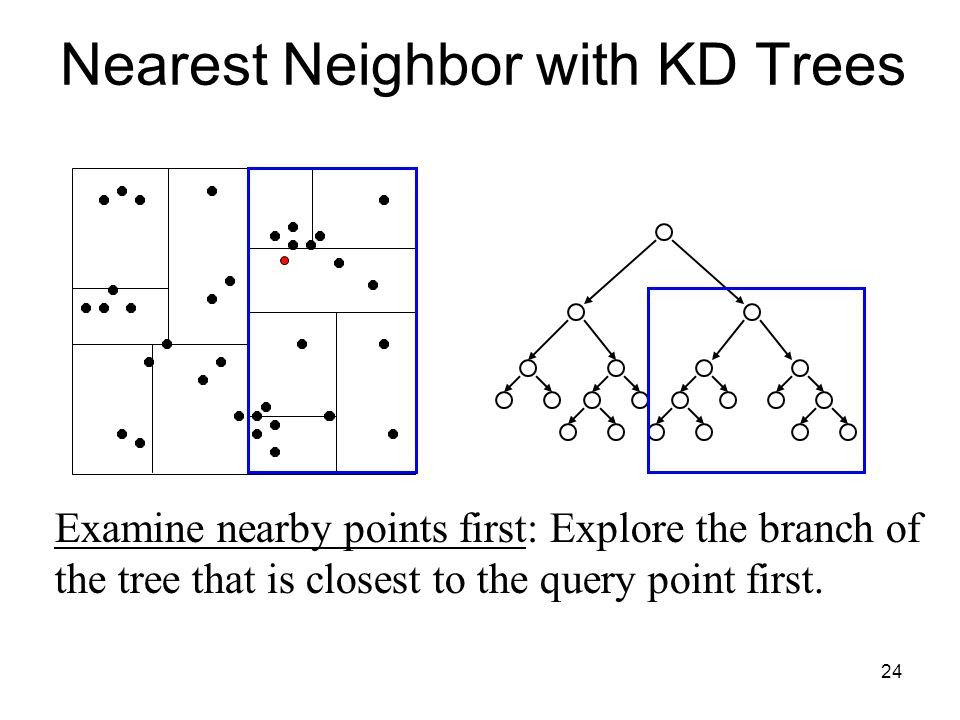
Nearest Neighbor Search Ppt Download

Revisiting Kd Tree For Nearest Neighbor Search Youtube
Balltree kdtree and a brute force algorithm based on routines in sklearn metrics pairwise the choice of neighbors search algorithm is controlled through the keyword algorithm which must be one of.
Ball tree nearest neighbor. N samples is the number of points in the data set and n features is the dimension of the parameter space. The reason is that there is an overhead in preprocessing the data to build the tree at first this takes longer than a simple search through the points to check which is closest. The kd tree isn t suitable for finding the nearest player to the ball in a sports game. Balltree for fast generalized n point problems.
Nearest neighbor search nns as a form of proximity search is the optimization problem of finding the point in a given set that is closest or most similar to a given point. Sklearn k nearest and parameters sklearn in python provides implementation for k nearest neighbors. As the k increases query time of both kd tree and ball tree increases. The kd tree is only suitable when the set of points is fixed.
The ball tree nearest neighbor algorithm examines nodes in depth first order starting at the root. Parameters x array like of shape n samples n features. A ball tree is a data structure that can be used for fast high dimensional nearest neighbor searches. It acts as a uniform interface to three different nearest neighbors algorithms.
Nearestneighbors implements unsupervised nearest neighbors learning. Sklearn neighbors balltree class sklearn neighbors balltree x leaf size 40 metric minkowski kwargs. Before this i have been using scikit learn s implementation of the ball tree nearest neighbour module to carry out my scientific calculations but it is not feasible when i have new data arriving and the entire ball tree has to be reconstructed every time. I need a method to construct a ball tree in an on line manner for nearest neighbour search.
I d written it for some work i was doing on nonlinear dimensionality reduction of astronomical data work that eventually led to these two papers and thought that it might find a good home in the scikit learn project which gael and others had just begun to bring out of hibernation. Closeness is typically expressed in terms of a dissimilarity function. During the search the algorithm maintains a max first priority queue often implemented with a heap denoted q here of the k nearest points encountered so far. Value of k neighbors.

Ataiya Kdtree File Exchange Matlab Central

K Nn 7 How To Make It Faster Youtube

Machine Learning Fast K Nearest Neighbour Kd Tree Part 6 Youtube
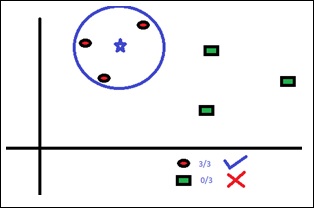
Machine Learning With Python Algorithms Tutorialspoint

Noisy Data Elimination Using Mutual K Nearest Neighbor For

Pdf A Survey On Nearest Neighbor Search Methods

Pdf Visual Computing Geometry Graphics And Vision

Tutorial 2 Creating Recommendation Systems Using Nearest

Ball Tree Explained In Simple Manner Linux Uncle

Location Difference Of Multiple Distances Based K Nearest

Machine Learning For Everyone

A New Fast Search Algorithm For Exact K Nearest Neighbors Based On

K D Tree In Python 3 Finale Youtube

Pdf K Nearest Neighbor Algorithm For Finding Soccer Talent
